# 导入包
import matplotlib.pyplot as plt
import numpy as np
# 准备绘图数据
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
# 设定图表形式
fig, ax = plt.subplots()
ax.plot(x, y)
# 显示图表
plt.show()
在这一部分,我们将学习和数据可视化相关的内容。首先我们将介绍Python绘图的基础库Mathplotlib,了解可视化绘图时的基础流程,再重点介绍Plotly交互式可视化库的使用。
Matplotlib 是 Python 中最常用的可视化工具之一,可以非常方便地创建不同类型的图表。Python的可视化包有很多,但是 Matplotlib 是最基本最常用的,因此需要对其概念有所了解。
import matplotlib.pyplot as plt)。(必须)plt.show())。(可选)# 导入包
import matplotlib.pyplot as plt
import numpy as np
# 准备绘图数据
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
# 设定图表形式
fig, ax = plt.subplots()
ax.plot(x, y)
# 显示图表
plt.show()

Matplotlib 提供了三种设置 matplotlib 选项的方式:
rcParams动态设置。style sheets。matplotlibrc设置文件。这三种方式的优先级别依次递减,rcParams最高,matplotlibrc最低。
rcParams动态设置默认设置为640*480 英寸(inches),通过figure.figsize选项进行更改。
plt.rcParams["figure.figsize"]=(6.4,4.8) #设置图片大小默认分辨率DPI为100,将其设置为300,以保证图片在印刷时具有足够的细节。
plt.rcParams["figure.dpi"] = 300 #设置图片分辨率Matplotlib 默认配置不支持中文字符,绘制的图像若使用中文会乱码,需要通过指定字体等设置让图形正常显示汉字。
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"]=(6.4,4.8)
plt.rcParams["figure.dpi"] = 300
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
year = [2017, 2018, 2019, 2020]
people = [20, 40, 60, 70]
#生成图表
plt.plot(year, people)
plt.xlabel('年份')
plt.ylabel('人口')
plt.title('人口增长')
#设置纵坐标刻度
plt.yticks([0, 20, 40, 60, 80])
#设置填充选项:参数分别对应横坐标,纵坐标,纵坐标填充起始值,填充颜色
plt.fill_between(year, people, 20, color = 'gray')
#显示图表
plt.show()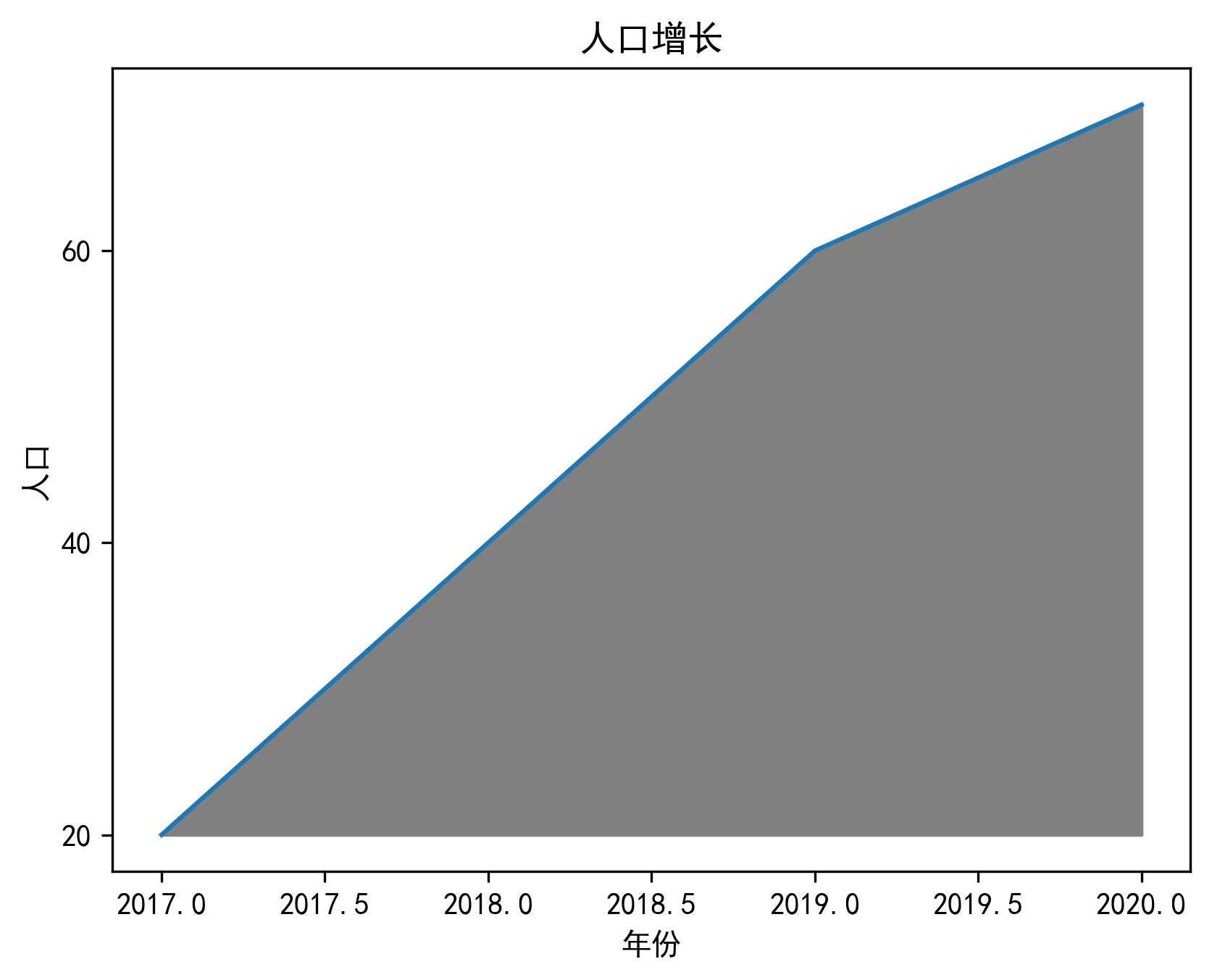
Plotly 是一个流行的开源图形库,用于创建高质量的交互式可视化。它支持多种编程语言,如 Python、R 和 JavaScript,但在 Python 社区中尤为受欢迎。Plotly 提供了一系列丰富的图表类型,包括但不限于折线图、散点图、柱状图、饼图、热力图、3D 图表等。
Plotly项目的创始人是Alex Johnson,是哈佛大学物理博士。该项目的参与者中有一位华裔女生,叫Baobao Zhang(张宝宝),是耶鲁大学政治学博士。Fernando Perez(IPython Notebook创始人)是该项目的顾问。
Plotly 的最大特点之一是其强大的交互性。用户可以缩放、平移、悬停(显示详细信息)等操作,这对于深入理解复杂数据非常有帮助。尽管功能强大,但 Plotly 的使用相对简单,特别是 Plotly Express 模块,它提供了一种更简洁的 API,可以用很少的代码生成复杂的图表。Plotly 生成的图表在视觉上具有吸引力,可以轻松定制以适应不同的演示风格。Plotly 可以输出为静态图片、HTML 文件,甚至可以嵌入到 Jupyter Notebook中。作为一个流行的库,Plotly 拥有广泛的社区支持和详尽的文档。
安装 Plotly 相对简单,通常使用 Python 的包管理器 pip 来安装。在命令行界面(如命令提示符、终端或 Anaconda Prompt)中运行以下命令:
pip install plotly如果您使用的是 Jupyter Notebook,可以在笔记本的一个单元中直接运行:
!pip install plotly这将安装最新版本的 Plotly。请确保您的 Python 环境已正确设置并具有互联网连接。
安装后,您可以通过在 Python 脚本或 Jupyter Notebook 中导入 Plotly 来开始使用它:
import plotly.graph_objects as go
# 或者
import plotly.express as pxPlotly绘图模块库支持的图形格式很多,其绘图对象包括如下几种:
Plotly Express 和 Plotly Graph Objects 是 Plotly Python 库中两个主要的模块,它们都用于数据可视化,但在使用方式和灵活性上存在一些重要的差异。通常,Plotly Express 足以应对大多数标准的数据可视化需求,而 Graph Objects 是那些需要特殊处理或具有特定设计要求的复杂项目的理想选择。
import plotly.express as px
import pandas as pd
df = pd.read_csv(R'../../data/csv/600519.csv')
fig = px.line(data_frame=df, x="day", y="close", title="Line Plot")
fig.show("svg")
注意:fig.show("svg")中的"svg")并非必需,是为了让Github网站在预览ipynb文件时能够显示绘图结果的折中办法,使用该参数后,Plotly的交互特定就没有了。如果要在线体验交互效果,推荐使用https://nbviewer.org/工具进行预览和体验。
import plotly.graph_objects as go
fig = go.Figure(data=go.Scatter(x=[1, 2, 3], y=[4, 5, 6]))
fig.update_layout(title_text="Detailed Custom Plot")
fig.show("svg")
图形的大小可以通过width和height参数指定,单位为px。
df3 = pd.DataFrame({
"姓名": ["小明","小红","张三"],
"英语":[64,84,69]
})
fig = px.bar(df3,
x="姓名",
y="英语",
width=600,height=600)
fig.show('svg')
可通过 hover_data 参数指定鼠标悬停时的数值:
fig = px.bar(df1,
x="name",
y="age",
color="age",
hover_data = ['score']
)
fig.show()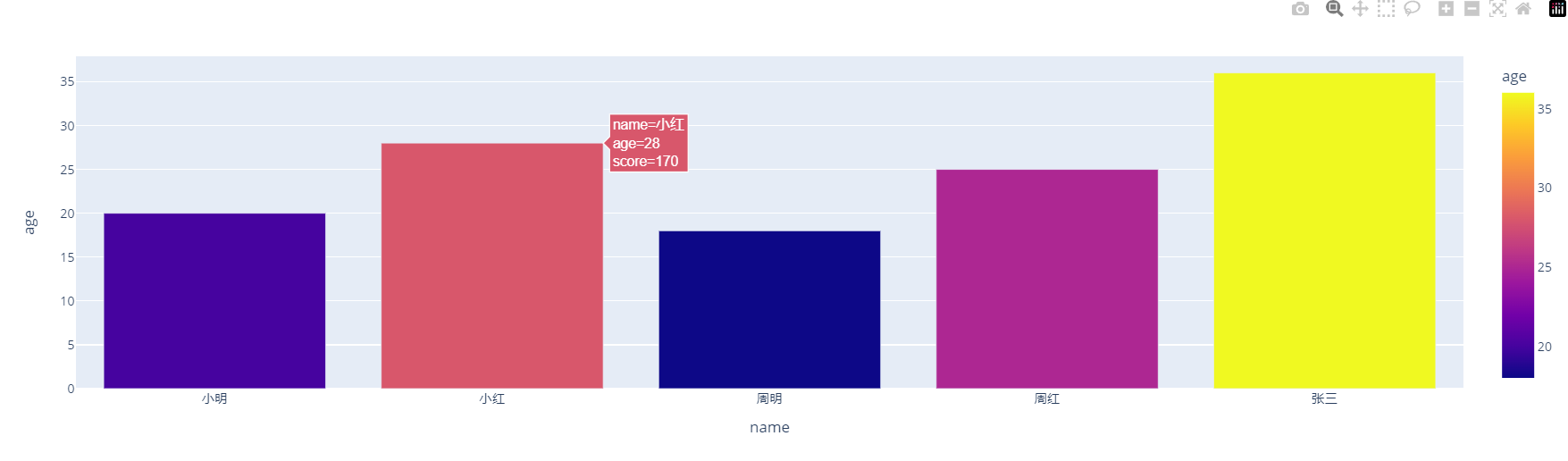
颜色可用于表示连续或离散数据。使用不同的颜色代表不同的分类数据,但 Plotly 也可以用颜色表示连续值。
颜色序列是要映射到离散数据值的颜色列表。与连续色阶不同,使用颜色序列时不会发生插值,并且每种颜色都按原样使用。颜色序列默认值取决于活动模板的 layout.colorway 属性,可以使用许多 Plotly Express 函数的 color_discrete_sequence 参数显式指定。
Plotly Express 提供了多种内置的离散颜色序列(colors.qualitative),这些颜色序列设计用来为分类数据的不同类别提供视觉区分。以下是一些常见的内置离散颜色序列:
使用如下的代码,可以查看全部内置的离散颜色:
fig = px.colors.qualitative.swatches()
fig.show('svg')
当你使用 Plotly Express 创建图表时,可以通过 color_discrete_sequence 参数指定这些序列中的任何一个。例如:
import plotly.express as px
df = px.data.gapminder().query("year==2007")
# 使用内置的离散颜色序列
fig = px.bar(df, x="continent", y="pop", color="continent",
color_discrete_sequence=px.colors.qualitative.G10)
fig.show('svg')
在这个例子中,条形图使用了 Plotly Express 内置的 G10 离散颜色序列来区分不同的大陆。这些预定义的颜色序列方便了用户在创建图表时快速选择合适的颜色组合,以增强数据的可视化效果和解读性。
要在 Plotly Express 中自定义离散颜色序列,你可以直接在 color_discrete_sequence 参数中指定一个颜色列表。这个列表应包含你想要用于图表中不同类别的颜色代码。颜色代码可以是十六进制的颜色代码(如 #FF5733),RGB 或 RGBA 格式(如 rgb(255, 87, 51) 或 rgba(255, 87, 51, 0.5)),或者是有效的 CSS 颜色名称(如 red)。
例如:
import plotly.express as px
# 示例数据
df = px.data.gapminder().query("year==2007")
# 自定义颜色序列
custom_colors = ['red', '#EF553B', '#00CC96', '#AB63FA', '#FFA15A']
# 创建条形图,使用自定义颜色序列
fig = px.bar(df, x='continent', y='pop', color='continent',
color_discrete_sequence=custom_colors)
fig.show('svg')
import plotly.express as px
# 示例数据,整理成长格式
df = px.data.tips()
df = df.groupby(['day', 'sex']).size().reset_index(name='counts')
# 创建堆叠条形图
fig = px.bar(df, x='day', y='counts', color='sex',
title="Total Counts by Day and Sex",
labels={'counts':'Total Counts'})
# 显示图表
fig.show('svg')
颜色还可以对应连续变量,如下:
import plotly.express as px
df = px.data.tips()
fig = px.pie(df, values='tip', names='day', color_discrete_sequence=px.colors.sequential.RdBu)
fig.show()
通过update_layout可以对图形的布局内容进行设置,比如title对应图形的标题,可以设置位置、内容、大小。
import plotly.express as px
df = px.data.tips()
fig = px.pie(df, values='tip', names='day',
color_discrete_sequence=px.colors.sequential.RdBu)
fig.update_layout(
title={
"text": "每日占比",
"y": 0.96,
"x": 0.5,
"xanchor": "center",
"yanchor": "top"
})
fig.show('svg')
这段代码参数的具体说明:
在 Plotly Express 中,可以通过 update_layout 方法来自定义图例(legend)的各个方面,包括其位置、方向、标题以及是否显示图例等。下面是一些常见的设置图例的方法:
你可以设置图例在图表中的位置(比如 ‘top left’, ‘bottom right’ 等),以及是水平显示还是垂直显示:
import plotly.express as px
# 示例数据和绘图
df = px.data.gapminder().query("year==2007")
fig = px.scatter(df, x="gdpPercap", y="lifeExp", color="continent")
# 更新图例设置
fig.update_layout(
legend=dict(
yanchor="bottom", y=1,
xanchor="right", x=1,
orientation="h" # 水平显示图例
)
)
# 显示图表
fig.show('svg')
在这个例子中,x 和 y 控制图例的位置,xanchor 和 yanchor 决定了这个位置是相对于图例的哪个点(例如 ‘bottom’ 表示位置是相对于图例的底部),orientation="h" 将图例设置为水平显示。
可以通过 update_traces 方法更改图例标题:
fig.update_traces(showlegend=True, name="新图例标题")有时你可能不想显示图例,可以这样设置:
fig.update_layout(showlegend=False)饼图(pie)用于表示不同分类的占比情况,通过弧度大小来对比各种分类。饼图通过将一个圆饼按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块(圆弧)表示该分类占总体的比例大小,所有区块(圆弧)的加和等于 100%。
适用于类别变量,对比类别变量的数值大小,建议类别不超过 9 个,过多的类别建议合并。
import pandas as pd
import plotly.express as px
fruit = pd.DataFrame({
"name":["苹果","香蕉","梨","菠萝","葡萄"],
"number":[1000,800,600,2000,2500]
})
fig = px.pie(fruit,names="name",values="number")
fig.show()
还可以通过fig.update_traces对饼图中的说明文字进行设定:
import pandas as pd
import plotly.express as px
数据表 = pd.read_excel(R'../../data/xls/招聘信息v2.xlsx')
fig = px.pie(数据表, names='学历要求')
fig.update_traces(textinfo='percent+label')
fig.show()
中空的饼图,也叫环圈图,或甜甜圈图。使用hole参数,可以指定中空的大小。
fig = px.pie(fruit,
names="name",
values="number",
hole=0.3, # 设置中间空心圆的比例:0-1之间
title="水果数量占比"
)
fig.show()
柱状图(bar plot)是用一定宽度和高度的矩形表示各类别频数多少的图形,主要用于展示类别变量的频数分布。

一个分类数据字段、一个连续数据字段
如果矩形为垂直方向,则称为柱状图,若为水平方向,则成为条形图。
分组柱状图,又叫聚合柱状图。当使用者需要在同一个轴上显示各个分类下不同的分组时,需要用到分组柱状图。
与并排显示分类的分组柱状图不同,堆叠柱状图将每个柱子进行分割以显示相同类型下各个数据的大小情况。它可以形象得展示一个大分类包含的每个小分类的数据,以及各个小分类的占比,显示的是单个项目与整体之间的关系。
导入包后,使用bar方法即可绘制柱状图,bar方法的参数详见:https://plotly.com/python-api-reference/generated/plotly.express.bar
import plotly.express as px 绘制基础柱状图时,只需要指定坐标轴对应的数据即可。
import plotly.express as px
import pandas as pd
df1 = pd.DataFrame({
"name": ["小明","小红","周明","周红","张三"],
"age": [20,28,18,25,36],
"score": ["150","170","160","168","154"]
})
fig = px.bar(df1,x="name",y="age")
fig.show()
可以使用color参数,对指定的变量使用颜色进行区分。不建议使用过多颜色对类别进行区分,会造成用户较重的认知负担。
注意上面的演示数据,已经按照类别计算好了总和这些必要数值。如果是原始数据,比如打开一个二维表后,要绘制某个变量的柱状图,则需要先准备好数据,才可以绘图。
准备单个变量柱状图的绘图数据,可以使用DataFrame中的value_counts().reset_index()两个方法,将类别变量计数后,转化为包含变量和技术的DataFrame。
from pyreadstat import pyreadstat
import pandas as pd
import plotly.express as px
调查数据, metadata = pyreadstat.read_sav(
R'../../data/sav/identity.sav', apply_value_formats=True, formats_as_ordered_category=True)
df_political = 调查数据['政治面貌'].value_counts().reset_index()
fig = px.bar(df_political, x='政治面貌', y='count',
labels={'count': '人数'})
# 显示图表
fig.show('svg')
还可以为不同类别增加颜色,使用颜色区分不同类别。颜色变量可以为类别变量,也可以为数值连续变量。
fig = px.bar(df1,
x="name",
y="age",
color="name" # 颜色参数
)
fig.show()
orientation的默认值为"v",若要绘制水平柱状图(也叫条形图),则设定其值为"h"即可。
df = px.data.tips()
fig = px.bar(df, x="total_bill", y="day", orientation='h')
fig.show()
color参数的值如果是类别变量,则会以类别变量为依据进行分组,并使用不同颜色加以区分。plotly.express中默认的分组柱状图为堆叠柱状图。
df2 = pd.DataFrame({
"姓名": ["小明","小红","张三","小明","小红","张三","小明","小红","张三"],
"科目":["语文","语文","语文","数学","数学","数学","英语","英语","英语"],
"得分": [58,78,84,90,71,90,64,84,69]
})
fig = px.bar(df2,
x="姓名",
y="得分",
color="科目")
fig.show()
还可以通过在Y轴上添加多组变量的方式,绘制柱状图。
df3 = pd.DataFrame({
"姓名": ["小明","小红","张三"],
"语文":[58,78,84],
"数学":[90,71,90],
"英语":[64,84,69]
})
fig = px.bar(df3,
x="姓名",
y=["语文","数学","英语"],
title="学生成绩对比"
)
fig.show()
还可以通过barmode参数,指定分组的模式,默认值为relative(堆叠柱状图)。当barmode为group时,为分组的数据在x轴并排显示,即分组柱状图。
fig = px.bar(df2,
x="姓名",
y="得分",
color="科目",
barmode='group')
fig.show()
Line Chart,基础折线图。折线图用于显示数据在一个连续的时间间隔或者时间跨度上的变化,它的特点是反映事物随时间或有序类别而变化的趋势。

数值变量、时间变量或有序类别变量
import plotly.express as px
df = px.data.gapminder().query("country=='China'")
fig = px.line(df, x="year", y="lifeExp", title='中国预期寿命')
fig.show()
import plotly.express as px
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", color='country')
fig.show()
import plotly.express as px
df = px.data.gapminder().query("continent == 'Oceania'")
fig = px.line(df, x='year', y='lifeExp', color='country', markers=True)
fig.show()
直方图(histogram)以矩形的面积表示每组数值的次数或百分比,是一种对数据分布情况的二维统计图表。直方图的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条(bar)的形式具体表現。直方图的长度及宽度可以表示数量上的变化,所以直方图可用于解读数值之间的差异。这一术语由英国统计学家卡尔·皮尔逊于1895年创立。
数值变量

直方图有时会与条形图混淆。直方图用于连续数值变量的描述统计,其中条柱表示数据范围,而条形图是分类变量图。一些作者建议条形图在矩形之间留有间隙以阐明区别。
默认情况下,使用组距中的频次作为矩形的高度。
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill")
fig.show()
还可以指定以百分比作为矩形的高度。通过参数histnorm指定。
df = px.data.tips()
fig = px.histogram(df, x="total_bill", histnorm='probability density')
fig.show()
在 Plotly Express 中设置直方图的组距(也称为 bin size),可以通过 nbins 参数或者更详细的 histfunc 和 barmode 参数来实现。nbins 指定了直方图中 bin(箱子)的数量,而 histfunc 和barmode 提供了关于如何计算和显示直方图的更多控制。
fig = px.histogram(df, x="total_bill", nbins=10)
fig.show()
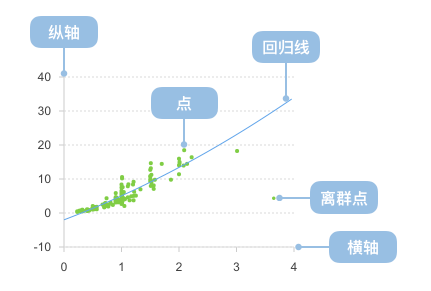
散点图也叫 X-Y 图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,散点图还可以观察极值点。
通过观察散点图上数据点的分布情况,我们可以估计出变量间的相关性。如果变量之间不存在相互关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据点就会相对密集并以某种趋势呈现。
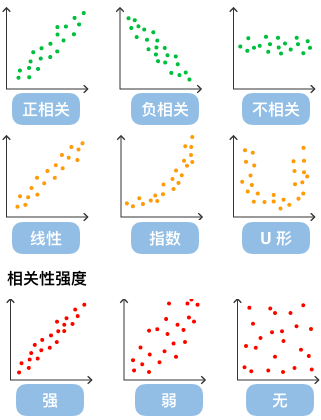
数值变量
import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length" )
fig.show()
趋势线帮助识别数据中的整体趋势或模式,无论这些趋势是线性的、指数的还是多项式的。例如,在时间序列数据中,趋势线可以揭示上升、下降或稳定的趋势。对于包含大量散点的图表,趋势线可以简化信息,使得观察者更容易理解数据的总体方向。趋势线可以用来预测未来的数据点,尤其在线性或其他简单模型中。在散点图中,趋势线可以帮助判断变量之间的关系强度。趋势线越接近所有点,关系就越强。
import plotly.express as px
df = px.data.tips()
fig = px.scatter(df, x="total_bill", y="tip", trendline="ols")
fig.show()
Plotly 可以非常方便地为多组变量绘制散点图,进而对比多个变量的差异。可以通过颜色、符号的不同,区分不同变量。
import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species", symbol="species")
fig.show()
箱形图(英文:Box plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因图形如箱子,且在上下四分位数之外常有线条像胡须延伸出去而得名。箱形图于1977年由美国著名统计学家约翰·图基(John Tukey)发明。它能显示出一组数据的最大值、最小值、中位数、及上下四分位数(五数概括)。
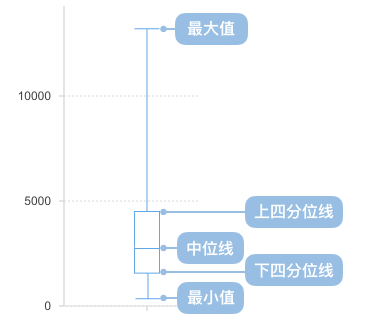
从箱形图中我们可以观察到:
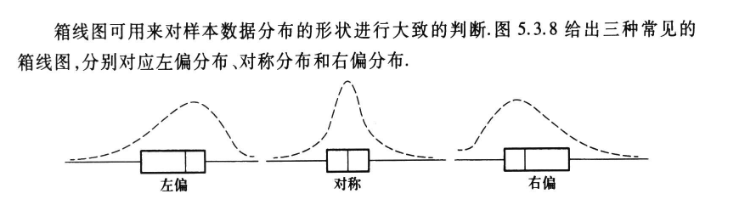
import plotly.express as px
df = px.data.tips()
fig = px.box(df, y="total_bill")
fig.show()
绘制对比箱线图(Boxplot)是一种展示不同类别或组数据分布的有效方式。
import plotly.express as px
df = px.data.tips()
fig = px.box(df, x="time", y="total_bill")
fig.show()
在一个图中并排展示多个组的箱线图,可以直观地比较这些组在统计上的差异,比如哪个组的中位数更高,哪个组的数据变异更大等。
import plotly.express as px
df = px.data.tips()
fig = px.box(df, x="day", y="total_bill", color="smoker")
fig.show()
旭日图(Sunburst Chart)是一种现代饼图,它超越传统的饼图和环图,能表达清晰的层级和归属关系,以父子层次结构来显示数据构成情况。旭日图中,离远点越近表示级别越高,相邻两层中,是内层包含外层的关系。

import plotly.express as px
tips = px.data.tips()
fig = px.sunburst(tips,
path=['day','time','sex'],
values='total_bill'
)
fig.show()